Changing texture with prompting. At coarse layers, we use the prompt "A teddy bear on tabletop" to fix the layout. Then at fine layers, we use "A teddy bear with the texture of [fleece, crochet, denim, fur] on tabletop". (Youtube link)
GigaGAN: Large-scale GAN for Text-to-Image Synthesis
Can GANs also be trained on a large dataset for a general text-to-image synthesis task? We present our 1B-parameter GigaGAN, achieving lower FID than Stable Diffusion v1.5, DALL·E 2, and Parti-750M. It generates 512px outputs at 0.13s, orders of magnitude faster than diffusion and autoregressive models, and inherits the disentangled, continuous, and controllable latent space of GANs. We also train a fast upsampler that can generate 4K images from the low-res outputs of text-to-image models.

Disentangled Prompt Interpolation
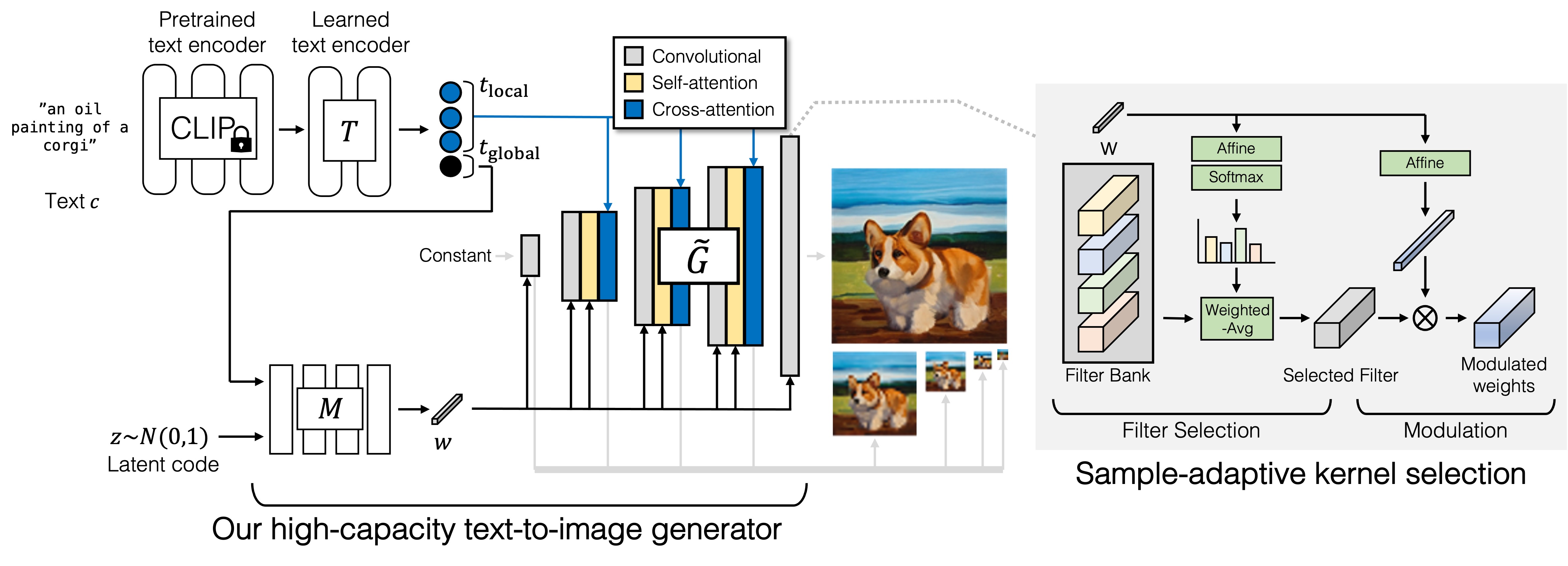
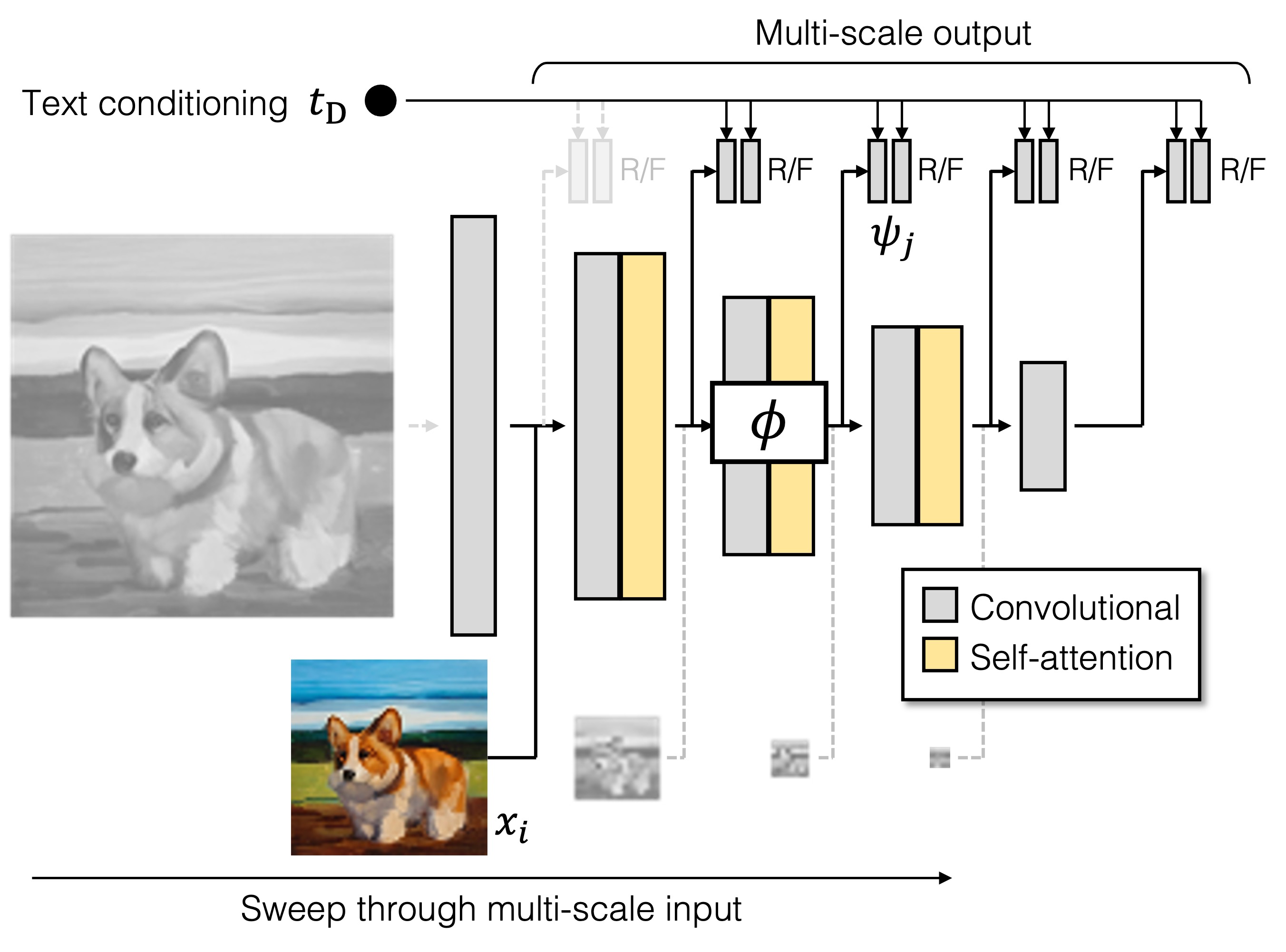
GigaGAN comes with a disentangled, continuous, and controllable latent space.
In particular, it can achieve layout-preserving fine style control by applying a different prompt at fine scales.
Changing style with prompting. At coarse layers, we use the prompt "A mansion" to fix the layout. Then at fine layers, we use "A [modern, Victorian] mansion in [sunny day, dramatic sunset]". (Youtube link)